
Where Big Data Fails…and Why
When this framework was first published in 2011, big data was just emerging as a mainstream discussion. At that time, the enthusiasm and optimism about big data was unbridled.
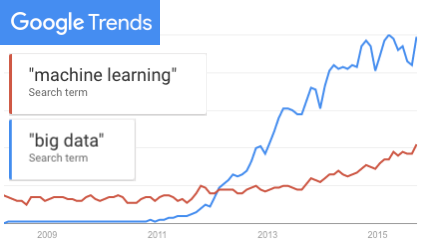
Today, the bloom is off the big data rose. Already on the downslope of Gartner’s 2014 Hype Cycle, the category was removed entirely from the 2015 report, replaced with the category of machine learning.
Machine Learning is the New Big Data
This is progress. Machine learning has a legitimacy that the term, big data, lacks, earned over decades of research and demonstrated in powerful, web scale applications.
But machine learning is data-driven. And the most celebrated approaches to machine learning, deep learning, require vast amounts of (big) data to work effectively.
In this respect, it feels like 2011 all over again. (A big data rose by any other name…?) As machine learning technologies are commoditized, people may inadvertently apply these technologies in hostile data environments.
In order to understand where data-driven applications thrive and where they fail, you need to recognize whether you’re working in a big data or small data environment.
Small Data Problems
Big data is plagued with small data problems. As the subjects of interests become more specific, the data available to describe these interests quickly thins out.
Social networks such as Facebook and Twitter illustrate the paradox of small data problems in big data. These networks are obviously massive: hundreds of millions of users creating profiles and media that encode innumerable interests. However, with respect to any specific individual or interest, the data is often sparse.
What follows is an explanation of the small data problem in big data and how it encroaches on many lucrative markets.
Why Big Data Fails
The Cost-Performance Barrier
In order to see small data problems in big data, you need to appreciate the shape of the data. Big data isn’t some undifferentiated mass. The shape of the underlying data has a tremendous impact on the productivity of knowledge modeling solutions.
The figure below illustrates the shape of big data.
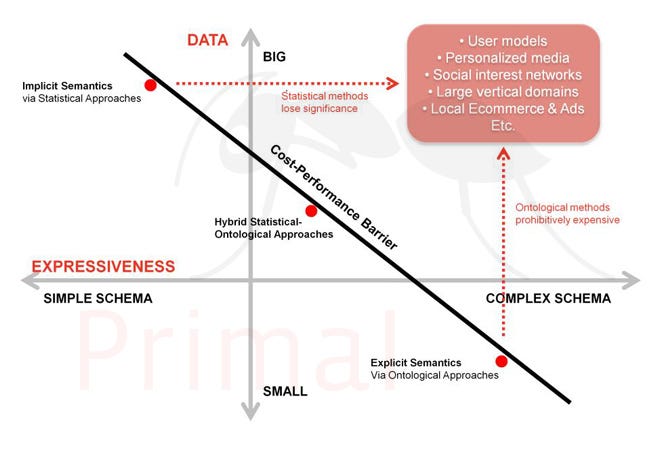
Domains of knowledge may be categorized along two axes: the breadth of data that encodes the knowledge (big data vs. small data), and the expressiveness or diversity of knowledge within the domain (complex vs. simple schema). Simple domains, such as lists of bicycle parts, are dominated by facts as objective, bounded knowledge; complex domains, such as politics, are characterized by their unbounded, subjective quality.
In a nutshell, big data fails when a knowledge modeling technology runs out of resources before the desired level of fidelity is attained.
In the figure above, this is illustrated as the cost-performance barrier. Three approaches for generating knowledge models are plotted along this cost-performance barrier: purely ontological (explicit) approaches, purely statistical (implicit) approaches, and hybrid statistical-ontological approaches.
Statistical methods thrive on big data. For these approaches, the resource shortage is in a lack of interest-specific data to mine. The quality of the model induced through these methods degrades as the underlying knowledge becomes increasingly diverse.
Manual approaches to knowledge engineering — such as building an ontology or database schema — face a different type of resource shortage. Within mass markets, methods that model the knowledge explicitly become prohibitively expensive. The knowledge becomes increasingly fine-grained and multi-faceted, surfacing ambiguities that are difficult to resolve. This increase in complexity imposes diminishing returns on the knowledge engineering effort and constrains ontological approaches to small markets.
Rarely are solutions either purely statistical or purely ontological. Any number of hybrid ontological-statistical approaches may be plotted along this continuum. Solutions often trade scalability and expressiveness, mixing statistical and ontological approaches to suit the characteristics of specific domains of knowledge.
Critically, hybrid statistical-ontological approaches can make trade-offs along this cost-performance barrier, but they cannot break through it. There is a coupling between the expressiveness of the knowledge model and the efficiency of retrieval and reasoning systems. As the knowledge model becomes increasingly complex, the costs in leveraging those models increase in lockstep.
Where Big Data Fails
Small Data Problems in Mass Market Opportunities
The cost-performance barrier leaves many lucrative markets inadequately served by data-driven approaches. The framework introduced above illuminates the common features shared across these markets that make them so challenging.
For ontological approaches, large collections of complex sub-domains within each area make knowledge engineering prohibitively expensive.
For statistical approaches, the relative scarcity of data pertaining to specific interests leaves large gaps in the resultant knowledge models.
Some of the most lucrative and enticing mass market opportunities exhibit these small data problems:
- Personalized media
- Content discovery
- Social interest networks
- Local ecommerce
- Hyper-targeting (advertising and marketing)
Conclusion
Big data is not the magic bullet many imagined it to be. And the same can be said of any data-driven technology. Analytical approaches inevitably break down when confronted with the small data problems of our increasingly complex and fragmented domains of knowledge.
Cost is the barrier. Specifically, solutions must be devised where the knowledge modeling costs are far less sensitive to the complexity of the data. Although innovations within analytical approaches will continue to inch the cost-performance barrier forward, new perspectives are needed to tackle our most challenging domains of knowledge.
