
The History of the Semantic Web is the Future of Intelligent Assistants
The Semantic Web provides an enticing vision of our online future. This next-generation Web will enable intelligent computer assistants to work autonomously on our behalf: scheduling our appointments, doing our shopping, finding the information we need, and connecting us with like-minded individuals.
Unfortunately, the Semantic Web is also a vision that, to some, seems very distant, perhaps even outdated. It has been over a decade since it was popularized in a May 2001 article in Scientific American. Semantic Web researchers and engineers have been toiling even longer on the monumental technical and sociological challenges inherent in creating a global Semantic Web.
The good news is that we are seeing evidence today of its accelerating emergence. Although still far from its grand vision, there are available today small “local” versions of semantic webs and intelligent assistants. Consumers can begin using these intelligent assistants today; producers can begin incorporating this next-generation semantic data into their current business models and applications.
Paradoxically, the path to a global solution may evolve not only through the cooperation of a community, but through the selective forces of competition. As proprietary semantic networks and software agents vie for mass market dominance, winning technical and business models will emerge through a tapestry of data providers and services.
Semantic Web Past
The Semantic Web vision was popularized through a May 2001 Scientific American article by Tim Berners-Lee (the inventor of the World Wide Web), James Hendler, and Ora Lassila. (The vision itself is older; Berners-Lee presented it in 1994 at the first World Wide Web Conference. A companion article, The Semantic Web Revisited, by Tim Berners-Lee, Nigel Shadbolt, and Wendy Hall, in IEEE Intelligent Systems (May/June 2006), reinforced the vision, its progress and challenges.)
The vision is as intoxicating now as it was then: “A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities.” This Web of structured data would enable automated assistants (called software agents) to operate on our behalf, autonomously completing tasks, and in the process, greatly simplifying and enriching our online experience.
The Semantic Web is not a new computing environment but rather an extension of the existing Web. Semantic data that provides a machine-readable “meaning” of information is layered over the information that is provided for people. The power of semantic data is that software can process it.
Few would recognize much of this grand vision in our current Web. The Social Web of people collaborating and participating online, overwhelms any discussion of the present or future Web. So what happened along the road to the Semantic Web?
The short answer is complexity, compounded across many different aspects. Building a global Semantic Web is an extremely complex undertaking. The engineers and scientists working on this problem are obviously quite familiar with this complexity. Even in that early Scientific American article, the authors delivered a message of compromise, noting that paradoxes and unanswerable questions must be tolerated in order to achieve the versatility needed for a global system.
Semantic Web researchers and engineers have managed this complexity admirably, navigating the necessary trade-offs in the pursuit of versatility and broad application. But the challenge is that the complexities of the Semantic Web extend well beyond architecture, beyond what was scoped by the Semantic Web working groups.
At some point, if the Semantic Web is to be truly global and truly semantic, its complexity cannot be compromised without losing the essence of the thing. The Semantic Web becomes a different kind of web entirely.
Complexity of Semantic Web Technology
The complexity of the Semantic Web is compounded across multiple levels. First, there is complexity in the Semantic Web technology stack (Figure 1). New languages and knowledge representation frameworks are layered on the Web’s basic hypertext standards and protocols.
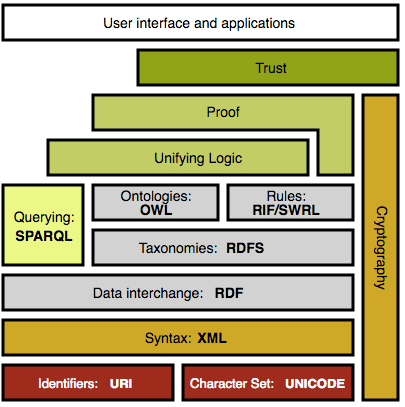
The simplicity of the World Wide Web was a huge factor in its rapid adoption and proliferation as a mass market network. That simplicity made the Web accessible to non-technical people who jumped right in and began creating content.
In contrast, the Semantic Web stack is much more complicated, prohibitively so for many who create content for the Web. As a result, there has been little content created specifically to populate the Semantic Web. The dominant approach at the moment is one of translating existing content such as documents and databases into standardized data formats.
But data and semantic data are different animals.
Complexity of Semantics
The field of semantics is far more abstract than documents or databases. It is the stuff of thought, a language for making meaning and expressing knowledge.
Knowledge representation is the science of expressing this abstract domain in formal computer models. The inherent complexity of semantics and knowledge representation imposes serious challenges on building a global Semantic Web.
Beyond representing and modelling knowledge, there are imposing challenges in the properties of semantic data. The first is in its scale. Semantically annotated information is much larger than the information it describes. Imagine the scale of a global Semantic Web, where the meaning of everything is described in this formal, highly structured (and necessarily inflated) way.
The scalability problem is compounded by another nagging reality of semantics. “Meaning” is extremely subjective and personal. For all but the most mundane facts (which excludes the vast majority of human discourse and knowledge), people don’t universally agree. A global Semantic Web must reconcile these personal semantics, particularly for consumer-facing applications where universality cannot be imposed.
In designing the Semantic Web, necessary compromises were made between the realities of how we think and make meaning, and those of a distributed, global computing environment. Thanks to the efforts of the Semantic Web community, we now have a tremendously versatile and global platform for data interoperability. Conceptually, we also have a container for the Semantic Web.
But what about the semantic content to fill it?
Semantic Web Present
Many presentations on the state of the Semantic Web show the familiar “layer cake” (Figure 1) and how the Semantic Web community is steadily making progress up that stack. However, we certainly do not have to wait until everything on that to-do list is complete before we can implement semantic applications.
One way to start is by taking an insular approach: just as an individual website is a microcosm of the Web, we can build small local versions of semantic webs. These initiatives provide concrete examples of the present utility of semantic technologies, as well as a glimpse into the future of a global Semantic Web. Taken together, aspects of the Semantic Web are available to consumers and producers right now.
Linked Data
In 2006, Tim Berners-Lee proposed a rebranding of sorts for the Semantic Web to the Data Web. At a TED talk in 2009, he focused on Linked Data. It refers to a method for publishing and sharing data over the Internet. While the World Wide Web refers to a web of linked documents, Linked Data refers to a web of linked data. In the aggregate, Linked Data represents an open, distributed database of information (Figure 2).
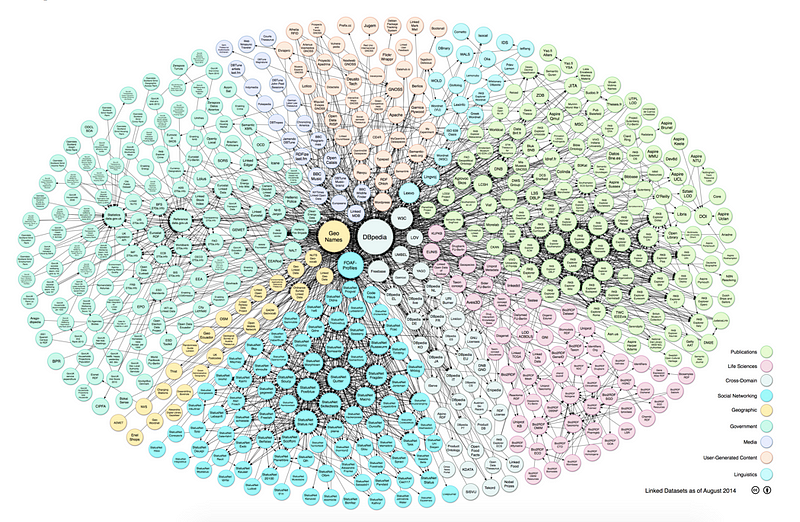
While the web of documents and the web of data may flow over much of the same Internet infrastructure, they are as dissimilar as documents from databases. Compare the breadth of applications of documents to that of databases and you will begin to get a sense of the transformative power of Linked Data. Linked Data provides a way for machines to join information together in complex ways.
The power to use Linked Data to support complex data combinations is what separates a web of data from a web of documents. In your applications, you can leverage the benefits of data reuse, extending proprietary content with data from public sources, and cooperating with external parties.
This structure is also moving into the Web of documents. Standardized vocabularies such as schema.org are being supported by major players such as Google, Bing, and Yahoo!, which is in turn driving widespread adoption of microdata formats within HTML documents. The Web of documents is being transformed into a Web of data.
Although not always under the banner of the Semantic Web, some organizations embody aspects of the Semantic Web vision in their use of software agents, distributed web services, and semantic data. Google and Apple are two notable examples, among many.
Google’s Freebase and Knowledge Graph
Tools are emerging to help people more effectively use Linked Data. Freebase from Google (Figure 3) was one example of a proprietary graph-based database that leveraged Linked Data. (The service was shut down by Google in August 2016.)
Freebase contained millions of facts about a variety of topics: people, geography, entertainment, etc. This data was contributed by the Freebase community of users, as well as gathered from Linked Data and unstructured sources on the Web. It was much like Wikipedia in its content, but much different in its form.
Wikidata is another Wikimedia project that aims to provide a free knowledge base that can be accessed and edited by humans and machines alike.
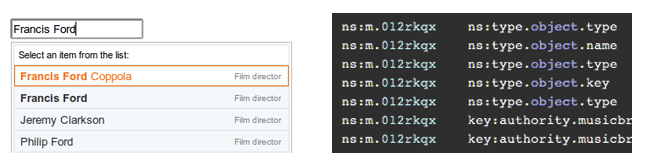
As a structured database, Freebase could be queried by other applications. The company provided API services that allowed developers to easily incorporate the data into their applications. Semantic search engines, educational tools, and mash-ups of popular culture such as movies and music were all enabled through Freebase.
A more pervasive asset within Google is its Knowledge Graph. This semantic knowledge base used by Google to enhance its search results with facts. It provides structured and detailed information about universal topics of interest, such as people, places, and things.
Knowledge Graph is an important part of Google’s plans to provide more automated user experiences. As we’re building a more Semantic Web, it becomes infrastructure not just for people, but for machines, as well.
Which is where we’re heading next.
Intelligent Assistants: Apple’s Siri and Google Now
Instead of just retrieving information, Apple’s Siri is a software agent that helps people complete their online tasks more easily. Siri is able to decipher speech and engage multiple services on behalf of the user.
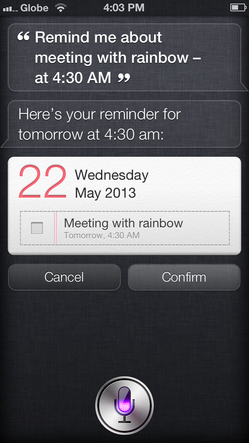
The initial set of tasks supported by Siri focused on the mobile Internet consumer: booking reservations at restaurants, checking the status of flights, or coordinating activities (Figure 4). Siri is now moving to other devices and platforms, including vehicles.
Another prominent example of software agents is Google Now. Similar to Siri in function and positioning, it answers questions, makes recommendations, and performs tasks on a person’s behalf. Google Now also provides autonomous services, proactively predicting and fulfilling needs.
This interoperability of software agents across a web of machines is a key aspect of the Semantic Web vision. Beyond acting as a web of documents or data, the Semantic Web becomes a web of machines able to communicate and co-operate without human intervention.
In these local examples of semantic webs we have several of the key aspects of the original Semantic Web vision. Software agents and services are collaborating over a distributed web of semantic data. Proprietary technologies are addressing gaps in the open infrastructure to make workable semantic applications a present reality for consumers.
Semantic Web Fast-Forward
Of course, this snapshot of small local semantic webs needs to be placed in the context of the rate of change. How quickly are we moving towards a fully realized and global Semantic Web?
It’s difficult to point to objective measures of growth across such a distributed environment. But consider the following markers:
- We are seeing an accelerating increase in the amount of Linked Data, reminiscent of the initial growth in the document Web during the mid-nineties.
- Major companies such as Google and Facebook are making their semantic data assets a focal point of their product development and marketing initiatives.
- Intelligent assistants such as Microsoft Cortana, Siri and Google Now have catalyzed a cottage industry of start-ups, representing a diverse range of automated services.
We are witnessing an accelerated emergence of new semantic technologies and services. A confluence of trends in the business and technology landscape is creating a virtuous cycle of innovation.
Semi-Structured Data and Social Media
While the working groups of the Semantic Web laid the technical foundation, it was the class of Web 2.0 companies that really got the structured-data ball rolling.
Documents alone generally do not provide that structure. While natural language has a structure that humans can interpret, it is not structured in a way that is easily parsed by machines. Humans are expected to “read into” natural language’s hidden implicit meanings, an ability that is very difficult to mimic in computer systems.
That began to change with the introduction of social tagging, which has become a mass market phenomenon. Popular services like Wikipedia, Flickr, and YouTube include simple social tagging mechanisms in their content creation processes. These tags comprise simple keywords that describe the meaning of the content. They are used on all sorts of content, including articles, blogs, and multimedia such as videos, photos, and music.
Social tagging has become ubiquitous, incorporated into the content creation and management systems of computer operating systems, productivity applications, enterprise applications, search engines, blogs, retail stores, and many others. As such, Web 2.0 social processes for creating content generated an abundance of semi-structured data online.
Big Data, Better Algorithms
Thanks to Web 2.0, semantic technologists have a wealth of big data to invest in their systems. While semi-structured data sources are rather impoverished in and of themselves, they can become quite powerful when examined in the aggregate and in large doses.
The more semi-structured and structured data you provide to semantic technologies, the more effective they become. Semantic technologies have a research legacy dating back decades. However, today, we have many orders of magnitude more data and computing power available for research and applications in semantic technologies. With greater quantities of data, the algorithms become more effective.
Similarly, as the amount of data increases, the algorithms need less sophistication. In a landscape of small data, the algorithms must be very smart, which in turn greatly narrows the number of contributors. However, big data eases this burden and provides more of a democratization of semantic technologies, reducing the resources and expertise needed to contribute new products and services.
Ecosystem for Sharing and Interoperating
Another contributor to this accelerating emergence of a global Semantic Web is a rapidly maturing distributed Web architecture. Most major online services are providing publicly accessible APIs that allow independently developed software systems to interoperate.
This environment is an extremely important part of a global Semantic Web, as it allows semantic technologies to cooperate on very large problems instead of tackling them independently. Creating rich semantic representations of information is extremely difficult. Semantic technologies must transform the implicit and hidden meaning in natural language to make it explicit and machine readable.
As an example, consider the mundane task of creating a semantic representation for a chunk of unstructured text, a frequent chore in semantic applications.
Under a collaborative model, different organizations can each contribute a piece of the solution. One semantic technology service might analyze some unstructured text to extract the people, places, and things discussed within the text. Another service might categorize this text into its broad themes or topics. Yet another might assess the authority of the document; another service might indicate the broad emotional sentiments that are being expressed.
Note that no one service would effectively capture all the meaning in the text. But working together, the services can provide rich semantic representations of the information for machines to use.

This environment of abundant semi-structured data, increasingly powerful semantic technologies, and a rich ecosystem of distributed web services and Linked Data allows us to imagine and create robust semantic applications today (Figure 6). But more importantly, they are creating a virtuous cycle of innovation that is rapidly transforming the landscape of the Web.
Semantic Web Future Revisited
The Semantic Web vision deserves a renaissance. The ambitions for it were not unrealistic. However, the model that was so successful for the World Wide Web — open and community-powered — was not a realistic implementation path. Many of the key success factors behind the World Wide Web are missing from the Semantic Web. The technology is much more complex, the subject matter is far more abstract, and the aspects of scale are far more daunting. The Semantic Web needs a different success model.
We can find alternative success models in other examples of mass market networks. When we look at the rise of existing mass market networks in content, search, and social networking, we see examples of innovators demonstrating small local versions of the networks that prove their utility. Over time, these small networks grow to mass-market proportions. Standardization in technologies and business models comes later as winners emerge.
Similarly, a global Semantic Web will emerge first through small working examples: independent organizations providing microcosms of the Semantic Web. These self-contained services will piggyback on the infrastructure of the Web, using distributed web services, open technologies and data. But before they can be “of the Web”, open and global, these services need to first be “Semantic”.
The Semantic Web is here and the core aspects of the original vision remain. While not all of its champions are operating under the banner of the Semantic Web, they will operate their semantic networks and services on the shoulders of it. Different models with different names, weaving together a global network.
Originally published at Primal.com.
